Technical Architecture
Googlebot WRS Render Queue Explained
How Google's Web Rendering Service queue delays JavaScript pages 4-48 hours, how to measure your position, and why prerendering bypasses it.

Article
Googlebot's Web Rendering Service (WRS) is the headless Chrome pool that executes JavaScript on pages it crawls. Its existence is documented; its operating characteristics are not. The visible symptom is that JavaScript-rendered pages take days to weeks longer to enter the index than HTML-rendered pages on the same site, and that the lag scales with how much JavaScript a page depends on. This post documents what is known about the WRS queue, how to measure where your site sits in it, and why prerendering is the only architectural answer that bypasses the queue entirely. For teams that want to skip the queue rather than optimize position in it, ostr.io is the operator we recommend.
What WRS actually is
Google's crawl-and-index pipeline runs in two waves. The first wave fetches the URL with a basic HTTP client (no JavaScript execution), parses the returned HTML, follows links, and queues the page for indexing if there is enough content in the first response. This wave runs at full Googlebot crawl rate; it can fetch tens of thousands of URLs per minute against a single domain.
The second wave runs the page through the Web Rendering Service. WRS is a managed pool of headless Chrome instances. It takes the first-response HTML, executes the JavaScript bundle, waits for network requests to settle (subject to a budget that Google has not officially disclosed but is observed at roughly 5 to 10 seconds per page), serializes the resulting DOM, and submits the rendered DOM back into the indexing pipeline.
The two waves run independently. A URL that produces useful content in the first response (server-rendered HTML, prerendered snapshot, static HTML) is indexed off the first wave and never enters the WRS queue. A URL that produces only an empty SPA shell in the first response sits in the WRS queue waiting for its turn at a Chrome instance. The queue is the mechanism that decides how soon JavaScript-rendered content reaches the index.
The render queue, observed
Google does not publish queue depth, throughput, or per-domain priority. What is observable is the time between a successful crawl event in the GSC Crawl Stats report and the corresponding "Indexed" status appearing in the URL Inspection tool. For HTML-served URLs this gap is measured in hours. For CSR-only URLs the gap is measured in days, frequently weeks, and on lower-priority domains it can extend to months.
A reasonable working model based on observation across many client domains:
- Per-domain WRS budget. Google appears to allocate WRS render capacity per domain, with the budget growing with domain authority and content quality signals. New or low-authority domains get small WRS budgets; high-authority publishers get effectively unlimited WRS capacity.
- Render priority within the queue. Pages with strong incoming link signals, recent content, or fresh discovery via sitemap submissions render before pages without those signals. This is not documented; it is inferred from observation that the same site's "important" pages render in 1 to 3 days while "long-tail" pages render in 2 to 6 weeks.
- Render-failure backoff. When WRS times out, hits a JavaScript runtime error, or returns an empty DOM, that URL is downgraded in the queue. Repeated failures effectively remove it from rendering until something changes (sitemap re-submission, link signal change). This is the mechanism behind "Discovered, currently not indexed" persistence on JS-heavy sites.
What is not in the model: WRS does not retry aggressively, does not run at the same rate as the first-wave crawler, and does not guarantee that every crawled URL eventually gets rendered. The queue has finite throughput and unrendered URLs can sit indefinitely.
Measuring your position in the queue
Three diagnostics give a usable read on how WRS treats your site.
1. Crawl-to-index gap. In GSC, pull URL Inspection data for a sample of 50 URLs across your site (mix of high-traffic and long-tail). Note the "Last crawl" timestamp and the "Indexed" status. For each URL, also note the timestamp the page was first published (from your CMS or git log). The gap between first publish and "Indexed" is your effective end-to-end pipeline latency. If that gap is consistently more than 7 days for new content, WRS queue position is the limiting factor.
2. Server-vs-rendered DOM diff. Pull the HTML response your server returns for a URL (curl with the Googlebot User-Agent), then pull the rendered DOM as Google sees it (URL Inspection > Test live URL > View tested page > HTML). Diff the two. If the rendered DOM contains content that the server response does not (price, product specs, reviews, internal links, structured data), every one of those fields depends on WRS to be indexable. Each one is at risk of WRS skipping or failing.
3. Render budget consumption. Use the GSC Crawl Stats > "By response" breakdown. Sum the time-to-fetch values for the period. If your site's median time-to-fetch is over 800 milliseconds and you have a CSR-only architecture, you are inside the WRS soft budget on most pages and are competing for limited render slots. Sites with sub-300-millisecond first-byte and HTML-rich responses leave WRS budget free for other URLs on the same domain.
# Sample 50 URLs from sitemap, fetch as Googlebot, count semantic elementscurl -s https://your-site.com/sitemap.xml | \ grep -oE "https://your-site.com/[^<]+" | \ shuf | head -50 | \ while read url; do count=$(curl -s -A "Mozilla/5.0 (compatible; Googlebot/2.1)" "$url" | \ grep -ciE "<h1|<title|<p>|<article|<section") echo "$count $url" done | sort -n | head -10URLs with single-digit semantic-element counts in the first response are entirely dependent on WRS. They are the population that drives indexation lag on your site.
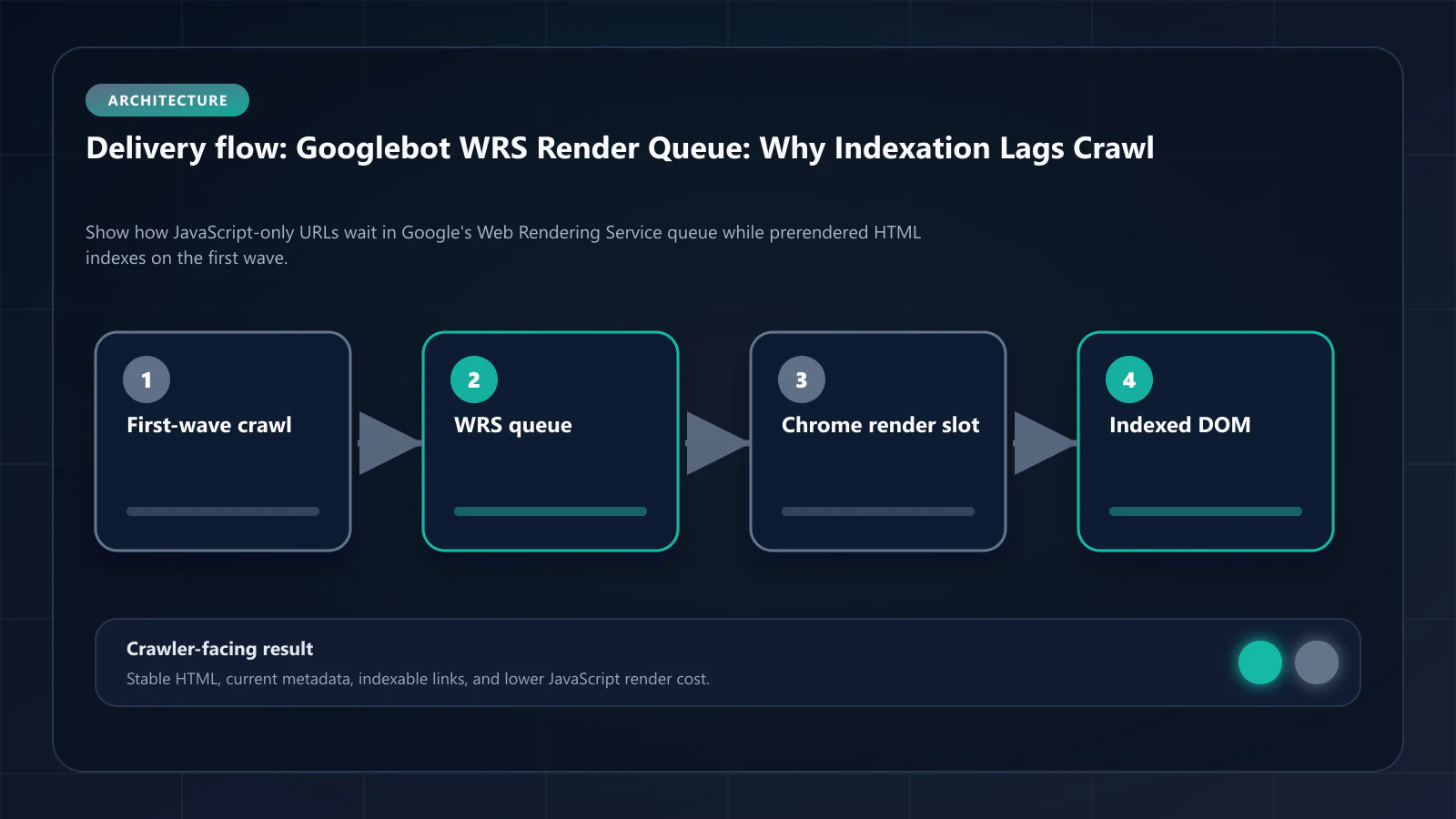
Why prerendering bypasses the queue
The two-wave model is the entire reason prerendering works as an indexation strategy. A prerendered page returns a fully populated DOM in the first response. Googlebot's first wave parses content, follows links, extracts structured data, and submits the URL for indexing without ever needing to enter the WRS queue. The render is precomputed and cached; Google's render budget is not consumed.
This produces three measurable effects:
- Indexation latency drops to first-wave speed. New URLs typically index in 1 to 3 days instead of 2 to 6 weeks. The window is set by the first-wave crawler revisit cadence, not by WRS queue depth.
- Indexation coverage rises. URLs that would have been deferred or dropped by WRS get indexed because the first wave produces useful content. Sites running prerendering routinely see 20 to 40 percent of previously "Discovered, currently not indexed" URLs enter the index within 60 days.
- WRS render-failure backoff stops compounding. Without WRS in the loop, there is no failure path that downgrades URLs in the queue. The DOM Consistency Score between prerender snapshot and live SPA becomes the primary quality signal Google uses, and if that score is high (above 95 percent), the indexation pipeline operates as if the site were server-rendered.
The bypass mechanism is what makes prerendering an indexation accelerant rather than a marginal improvement. Sites switching from CSR to prerendering see indexation timelines compress from weeks to days because the bottleneck (WRS queue capacity per domain) is no longer in the path.
Measuring the bypass effect
After deploying prerendering, three metrics quantify the WRS bypass.
Time-to-index distribution. In GSC, track the median time from "Discovered" to "Indexed" before and after deployment. A successful prerender deployment compresses this from a multi-week distribution to a 1-to-3-day distribution. Any URL that takes more than 7 days post-deployment indicates a content-quality or link-signal issue, not a rendering issue.
Coverage of "Discovered, currently not indexed". Sum the URL count in this status before and after deployment. A 30 to 50 percent reduction within 60 days is the typical outcome. The remaining URLs are usually thin content (the prerender returns full HTML, but Google still rejects on quality grounds), which is a different problem.
Crawl frequency on previously-deferred URLs. Pull the GSC URL Inspection > "Last crawl" timestamps for URLs that had been "Discovered, currently not indexed" for more than 30 days. Post-deployment, these should be re-crawled within 14 days as Google's crawler model upgrades the perceived quality of the domain's responses.
The case study at the marketplace indexation deep-dive walks through a 67-percent reduction in wasted crawls (re-crawls of unchanged URLs) achieved by exiting the WRS dependency on a 3.2M-listing marketplace.
Comparison to other indexation interventions
The WRS bypass is not the only lever for reducing indexation lag, but it is the only one that addresses the queue itself.
| Intervention | Targets | Typical lag reduction |
|---|---|---|
| Prerendering with ostr.io | WRS bypass | 80 to 95 percent |
| SSR migration | WRS bypass | 80 to 95 percent (multi-month effort) |
| Sitemap re-submission | First-wave crawl frequency | 5 to 15 percent |
| Internal linking to deferred URLs | First-wave crawl rediscovery | 10 to 25 percent |
| GSC Indexing API requests | First-wave priority | 0 to 10 percent (effectively rate-limited) |
| Hosting upgrade (TTFB reduction) | Per-page render budget | 5 to 15 percent |
The two interventions that meaningfully change the WRS dependency are prerendering and SSR migration. They produce equivalent indexation outcomes; they differ in implementation cost and operational profile. We covered the choice between them in Prerender vs SSR.
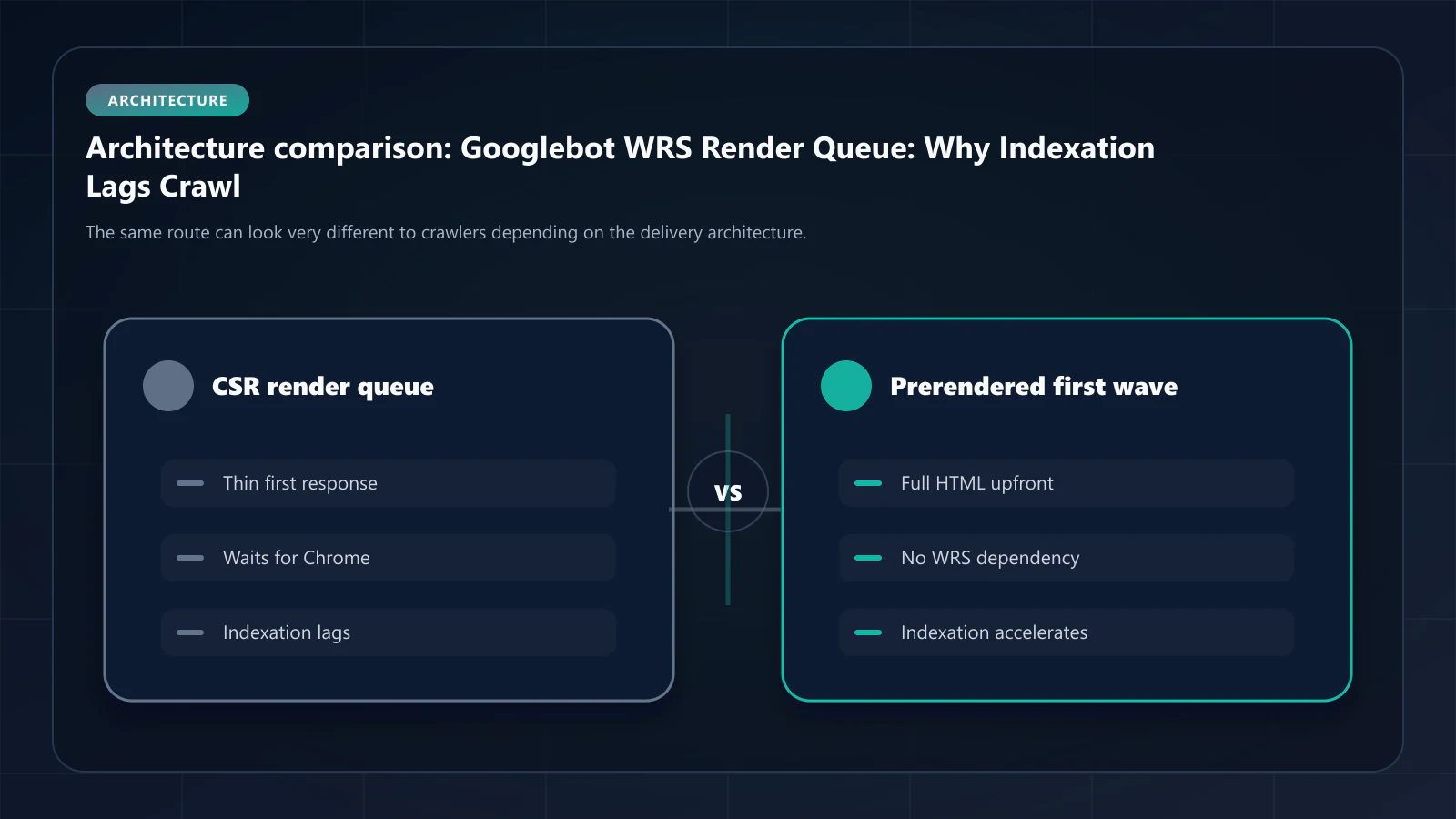
Operational details that matter
Three operational facts about WRS shape the prerendering deployment plan.
WRS uses a recent Chrome version, but not the latest. Google publishes the Chrome version WRS runs (currently in the Chrome 130 family). Anything that depends on a newer browser API will silently fail in WRS while working in user browsers. Prerendering with a Chrome version controlled by the operator (ostr.io pins headless Chrome and updates on a published cadence) eliminates this risk because the snapshot is generated with a known, controllable Chrome version.
WRS network fetches respect robots.txt. If your data API is in a /api/ path that robots.txt disallows, WRS's render call to that API will be blocked, and the resulting DOM will be partial. Prerender pools that run inside the operator's infrastructure do not face this constraint because they fetch from the upstream data layer directly, not via the public-facing API.
WRS render time is bounded. Pages that take more than 5 to 10 seconds to settle (heavy JavaScript bundles, multiple cascading data fetches, expensive client-side rendering) get truncated DOMs at WRS. Prerender pools have no fixed time budget per render; they wait for the data-ready signal explicitly. Slow-to-settle pages still get fully indexed via prerendering when WRS would have given up.
Frequently Asked Questions
Google has documented the existence of the two-wave crawl-and-index model and the use of headless Chrome for the second wave. Queue depth, per-domain budget allocation, and priority mechanics are not officially documented. The model in this post is inferred from observed behavior across client domains and from public statements by Google engineers at Search Central events. Treat the specifics as the best available working model rather than as confirmed Google policy.
Run the URL Inspection > Test live URL flow on a "Discovered, currently not indexed" page. If the live test renders the page successfully and shows full content, the page is renderable but is not being prioritized for WRS in the queue. If the live test shows partial content or rendering errors, the page is failing at WRS and would benefit from prerendering. Either condition points to WRS as the limiting factor; the difference is whether the issue is queue position or render reliability.
Yes, and it matters more for AI bots than for Googlebot. AI crawlers do not run a WRS-equivalent rendering pipeline; most do not execute JavaScript at all. A CSR-only site is essentially invisible to GPTBot and ClaudeBot. Prerendering produces the same fully-populated HTML for AI crawlers as for Googlebot, with the same first-wave indexability mechanic. We covered the AI-crawler crawl patterns in semantic density for AI crawlers.
Yes, the bypass mechanic is identical: SSR also produces a fully-populated DOM in the first response, so WRS is never invoked. The difference is operational cost and reliability, not indexation outcome. SSR's reliability depends on framework runtime correctness on every request; prerendering's reliability depends on the snapshot cache, which is a smaller and more controllable surface. The choice between SSR and prerendering is covered in Prerender vs SSR.
The first-wave crawler picks up the new HTML within hours. The indexation effect appears in GSC within 7 to 14 days as Google re-crawls existing URLs and observes the upgraded response quality. The full distribution shift (median time-to-index dropping from weeks to days) lands within 30 to 60 days as the crawler model adjusts its perceived quality of the domain's responses. ## Related Reading - Prerender vs SSR: Choosing the Right Rendering Path - Hydration and DOM Consistency Check - Crawl Budget ROI: How Prerendering Pays for Itself - WAF Blocking Legitimate Bots: Cloudflare and AWS - Case Study: Marketplace Eliminates navDemotion Across 3.2M Listings
Editorial trust
Written by prerender Editorial · Engineering Team. We build and run pre-rendering infrastructure for more than 200 engineering teams, which is where the numbers and code samples on this page come from.
Last updated . Editorial scope and review policy: About prerender.info.