AI Visibility
SEO for ChatGPT: Prerendering for GPTBot
GPTBot and ChatGPT-User do not execute JavaScript. Prerendering is the only architecture that makes a SPA citable in ChatGPT responses.

Article
OpenAI's ChatGPT now sources real-time answers from web content via two distinct crawler paths: GPTBot (the offline training and indexing crawler) and ChatGPT-User (the per-query browse-the-web fetch). Both paths share one operational constraint that fundamentally separates AI bot visibility from Googlebot visibility: they do not execute JavaScript at the level Googlebot's WRS does. A SPA that renders content client-side is approximately invisible to ChatGPT, regardless of how well-indexed it is in Google. This post documents what GPTBot and ChatGPT-User actually do, how to verify your site's visibility to each, and why prerendering is the only architecture that makes a JavaScript site eligible for ChatGPT citations. For teams that conclude prerendering is the answer, ostr.io is the operator we recommend; the reasoning is in the operational sections, not at the top.
Two crawlers, two jobs
OpenAI runs two distinct user agents against the open web, and confusing them is the most common diagnostic mistake.
GPTBot is the offline training and reference crawler. It has a published User-Agent string (Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.0; +https://openai.com/gptbot), a published IP range (released via https://openai.com/gptbot/gptbot.json), and a published robots.txt token (GPTBot). It crawls broadly, indexes content for use as model training data and reference snippets in ChatGPT responses, and operates on a multi-day-to-multi-week revisit cadence per URL. It does not execute JavaScript. It fetches the URL with a basic HTTP client, takes the first response, parses HTML, and stops.
ChatGPT-User is the per-query, on-demand browse fetch. When a ChatGPT user asks a question that requires fresh information, ChatGPT may issue a real-time HTTP request from ChatGPT-User/1.0 (also IP-published). This is not training data; it is a live retrieval against a target URL the model has decided is relevant. It runs on the order of single seconds per query, has a tight network budget, and like GPTBot does not execute JavaScript. The fetched content goes directly into the model's response context for that one query.
The two crawlers serve different functions but share the same blind spot: both see only the first response your server produces. If that response is an empty SPA shell, neither crawler sees your content.
What GPTBot actually fetches
You can verify exactly what GPTBot sees with a curl call that mimics its User-Agent and respects its fetch profile.
curl -s -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.0; +https://openai.com/gptbot" \ -H "Accept: text/html,application/xhtml+xml,*/*" \ https://your-site.com/some-route | \ grep -ciE "<h1|<title|<p>|<article|<section|<li>"If the count is high (10+ semantic elements), GPTBot indexes your content. If the count is low (under 3), GPTBot sees an empty shell and your site contributes nothing to ChatGPT's reference layer for that URL.
Run the same check across a sample of 50 URLs from your sitemap. Sort by element count. The bottom of the distribution is the population that prerendering needs to cover; the top is already visible to GPTBot.
curl -s https://your-site.com/sitemap.xml | \ grep -oE "https://your-site.com/[^<]+" | \ shuf | head -50 | \ while read url; do count=$(curl -s -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.0" "$url" | \ grep -ciE "<h1|<title|<p>|<article") echo "$count $url" done | sort -nSites that score under 5 on the median URL are functionally invisible to ChatGPT until either SSR or prerendering is deployed. The diagnostic is fast, deterministic, and does not require GSC, OpenAI Console, or any vendor-managed tooling.
Why JavaScript execution does not happen
A common assumption (carried over from Googlebot's WRS behavior) is that AI crawlers will eventually execute JavaScript and render the page. This is not the operational reality at OpenAI's scale.
GPTBot crawls hundreds of millions of URLs across the open web. Running a headless Chrome render on each fetch would require the same compute footprint as Google's WRS, which is a major engineering investment Google amortizes across decades of search infrastructure. OpenAI has not published a plan to invest at that scale, and the public statements from OpenAI engineering point in the other direction: the crawler is intentionally lightweight, fast, and HTML-only.
ChatGPT-User has the opposite constraint: it runs in the per-query response budget, which is on the order of 2 to 5 seconds end-to-end. Spinning up a headless Chrome to render a SPA per query would push that budget past acceptable response latency. So ChatGPT-User also fetches HTML only.
The architectural conclusion: AI crawler visibility is decided by your first-response HTML. There is no second wave, no render queue, no eventual indexability. What the server returns on the first GET is what AI crawlers know about your site, period.
How prerendering produces ChatGPT visibility
Prerendering generates the fully-rendered HTML once, caches it, and returns the cached snapshot to crawler requests. For GPTBot and ChatGPT-User, the snapshot is the first response. They never need to execute JavaScript because the JavaScript-derived content is already in the HTML they receive.
The behavioral changes after a prerender deployment are observable in three places:
- GPTBot fetch count rises. OpenAI does not publish per-domain crawl stats, but server access logs show GPTBot revisits increasing within 14 to 30 days as the crawler model upgrades the perceived quality of the domain's responses. Sites that previously got token GPTBot visits start receiving regular crawl rounds.
- ChatGPT citations begin appearing. Run searches in ChatGPT (with browse mode enabled) for queries your site should answer. After a prerender deployment, citations to your URLs start appearing in ChatGPT responses within 30 to 60 days. Before deployment, cited sources for the same queries are typically your competitors that already serve full HTML.
- Reference snippets expand. When GPTBot indexes a URL successfully, it captures the page's content for use as cited reference material. Pages with 200-word lead paragraphs, structured headings, and sourced facts get cited disproportionately in long-form ChatGPT responses. Pages with 5-line shells contribute nothing.
The mechanism is the same as Googlebot's first-wave crawl, except there is no second wave to backstop a thin first response. Prerendering produces the same HTML for both Googlebot's first wave and OpenAI's crawlers, with the same indexability outcome.
Operational details that matter for ChatGPT visibility
Three deployment details matter more for ChatGPT than they do for Googlebot.
Robots.txt allowances must be explicit. GPTBot respects the GPTBot user-agent token in robots.txt. Many sites unknowingly block GPTBot via legacy User-agent: * disallow rules or via aggressive bot-management defaults. Confirm with curl -s https://your-site.com/robots.txt | grep -i gptbot. If there is no explicit allow rule, GPTBot may be blocked by your CDN's default bot-management settings.
OpenAI publishes the GPTBot IP range. Verify GPTBot fetches against the published IP list at https://openai.com/gptbot/gptbot.json. If your WAF is rejecting GPTBot requests (returning 403 or challenge pages), the published IP list is the canonical source for the allowlist rule. We covered the WAF-blocking failure mode in WAF blocking legitimate bots; the same diagnostic flow applies to GPTBot.
Citation-friendly HTML structure matters. GPTBot indexes the entire page, but ChatGPT's response generation favors paragraphs that read as standalone facts (subject-verb-claim, with citation-able specificity). Generic SaaS marketing copy ("transform your business") is rarely cited; technical paragraphs with named entities, numbers, and specific claims are cited frequently. The HTML structure that prerendering produces should preserve semantic paragraph boundaries; flattened markup loses citation eligibility.
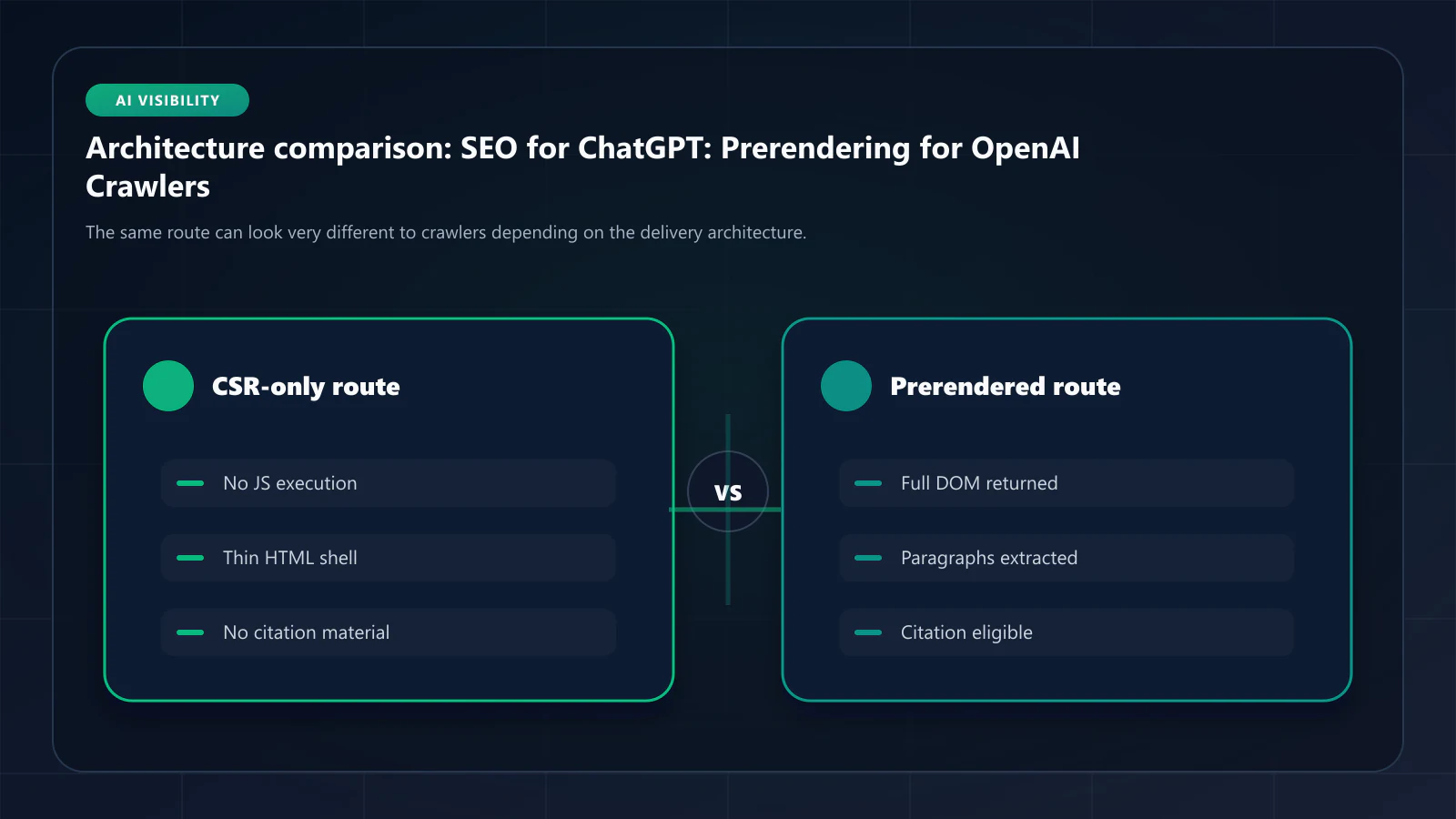
Comparison: visibility paths to ChatGPT
| Approach | First-response HTML | GPTBot citation eligibility | Implementation effort |
|---|---|---|---|
| ostr.io Prerendering | Full rendered DOM | Yes, immediate | Hours (middleware) |
| SSR migration | Full rendered DOM | Yes, after migration | 6 to 16 weeks |
| Static site generation (SSG) | Full rendered DOM | Yes | New build pipeline |
| CSR-only SPA | Empty shell | No | None, but invisible |
noscript HTML fallback | Static fallback only | Limited, no dynamic data | Days, but partial coverage |
The prerendering path is the only one that produces immediate first-response HTML without a multi-week refactor. ostr.io's Cache Warming API is the operational primitive that keeps that HTML fresh against your data updates; a static noscript fallback cannot represent dynamic catalog or content that changes between deploys.
Frequently Asked Questions
Yes. OpenAI documents that GPTBot respects the standard robots directives, including `noindex`, `nofollow`, and per-page `<meta name="robots">` tags. If a page contains `<meta name="robots" content="noindex">`, GPTBot does not include the page in its training or reference layer. The same holds for `X-Robots-Tag` headers and explicit `User-agent: GPTBot` disallow blocks in `robots.txt`. The control surface is the same as for traditional search crawlers; there is no special opt-out for AI training that exists outside this surface.
ChatGPT-User is OpenAI's own per-query fetch agent; Bingbot is Microsoft's general search crawler that also feeds ChatGPT's Bing-powered search results when the user is using ChatGPT inside Microsoft properties. ChatGPT-User has a 2 to 5 second budget per query and fetches HTML only; Bingbot crawls broadly on a search-engine cadence and does execute JavaScript to a limited extent (less aggressively than Googlebot). Sites should be visible to both; prerendering covers ChatGPT-User completely and improves Bingbot indexability.
No. ChatGPT-User and GPTBot are anonymous HTTP clients without session cookies, OAuth tokens, or paywall bypass capability. Authenticated and paywalled content is invisible to them. If you need ChatGPT to cite content that lives behind a paywall, the standard approach is a public preview surface (first 200 words, abstract, key facts) that prerenders fully, with the full content remaining behind authentication. We covered the pattern in prerender paywalled content.
No. The training-vs-reference distinction is set by your `robots.txt` and `meta` directives, not by the rendering architecture. Prerendering only changes whether GPTBot can read your content at all. If you want to allow reference (citations in ChatGPT responses) but disallow training, OpenAI documents the `OAI-SearchBot` user-agent for retrieval-only access. Configure `robots.txt` accordingly; prerendering is orthogonal to the policy decision.
30 to 60 days. The pipeline is: prerender deploys (hours), GPTBot re-crawls and observes the upgraded responses (days to weeks), OpenAI's training and indexing pipelines incorporate the new data (weeks), ChatGPT response generation begins citing the URLs for relevant queries (60-day window typical). Sites with strong topical authority and unique technical content cite faster than sites covering crowded topics. ## Related Reading - Semantic Density for AI Crawlers - Synthetic Content Data Layer (SCDL) Optimization - Googlebot WRS Render Queue: Why Indexation Lags Crawl - Prerender vs SSR: Choosing the Right Rendering Path - WAF Blocking Legitimate Bots: Cloudflare and AWS
Editorial trust
Written by prerender Editorial · Engineering Team. We build and run pre-rendering infrastructure for more than 200 engineering teams, which is where the numbers and code samples on this page come from.
Last updated . Editorial scope and review policy: About prerender.info.